


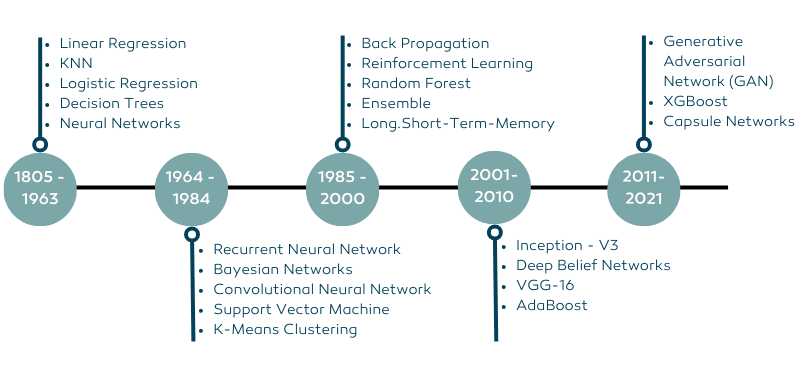
Una mirada a la historia
El aprendizaje automático o “machine learning” (ML) es un conjunto de técnicas de análisis de datos que permite a las máquinas aprender sin ser explícitamente programadas. Esto se logra mediante el uso de algoritmos que permiten detectar patrones en los datos de entrada y hacer predicciones o tomar decisiones basadas en esos patrones.
Ya en la década de 1980 se abordaba el potencial que tenía el Machine Learning en la solución de problemas complejos en campos de la computación (Jordan, 1986), así como el desarrollo de modelos como el árbol de decisión CART (Friedman, 1989) como señas del desarrollo que se avecinaba.
En la década siguiente la evolución de algoritmos continuó con hitos como la creación del entrenamiento por refuerzo “backpropagation” que es empleado para entrenar redes neuronales (Platt, 1990) conduciendo a una investigación más exhaustiva en este campo y sentando las bases de este. (Rumelhart, 1992) Es importante mencionar que fue en estos años cuando empresas como Google (con Google Brain) y DeepMind comenzaron a enfocar esfuerzos en el desarrollo de algoritmos.
Con el cambio de milenio llegaron las primeras oportunidades de aprendizaje en línea masivas sobre ML, como la impartida por Andrew Ng en la Universidad de Stanford que, al ser gratuita, colocó el aprendizaje de alta calidad en las manos de cualquier persona con un ordenador, permitiendo la popularización de estos campos y el impulso en el interés entre estudiantes y profesionales de todo el mundo.
El aprendizaje automático se ha vuelto entonces cada vez más popular en los últimos años debido a la creciente cantidad de datos disponibles y la necesidad de analizarlos de manera efectiva.
¿Qué aplicaciones son recurrentes?
En el sector bancario, el ML ha tomado terreno hasta tener una extendida presencia en diversas áreas. Por ejemplo, en el año 2001 Hand demostró que los modelos basados en árboles de decisiones podían ser muy efectivos para predecir el riesgo de impago en préstamos hipotecarios. (Hand, 2001) Para 2004 se estudiaba ya la estrecha relación entre la segmentación de clientes a partir del uso de minería de datos. (Verbeke, 2004) La implementación de ML en el sector bancario ha tenido como resultado un mejor desempeño que los métodos estadísticos tradicionales tanto en clasificación como en exactitud de predicción. (Leo M., 2019)
Esto puede ser útil para los gestores de carteras y otros profesionales financieros que buscan tomar decisiones informadas sobre cómo invertir el dinero de sus clientes.
Otra de las bondades de la aplicación de técnicas de ML es la detección de fraudes. Simeone et al demostraron la efectividad del uso de redes neuronales en este campo para las tarjetas de crédito (Simeone, 2004). Así, muchas instituciones financieras utilizan algoritmos para analizar transacciones y detectar patrones que indiquen actividad sospechosa. Esto puede ayudar a proteger a los clientes de la banca de posibles estafas y a las instituciones financieras de pérdidas financieras, un ganar-ganar por donde se quiera ver.
No podemos pasar por alto las mejoras para los usuarios como es la personalización de la experiencia del cliente. En 2005 D. Zakrzewska y J. Murlewski compararon análisis de clusterización bancaria bajo tres algoritmos: Densidad basada en DBSCAN, K-means y un proceso de segmentación de dos fases. (D. Zakrzewska and J. Murlewski, 2005) La personalización se basa en el análisis de los datos históricos que permiten ofrecer productos y servicios financieros que vayan estrictamente dirigidos en función de sus necesidades y preferencias, evitando entonces el bombardeo de spam con contenido que potencialmente no será de su interés y solo terminará saturando la bandeja de entrada del correo.
Descripción de los modelos
Algunas definiciones de las técnicas de ML entre las que se encuentran las anteriormente mencionadas son las siguientes:
– Regresión lineal: Usada para predecir un valor continuo a partir de una o más variables independientes. Ejemplo de esto es la predicción del monto de un préstamo basándose entre otras variables en el ingreso, edad e historial crediticio de una persona.
basándose entre otras variables en el ingreso, edad e historial crediticio de una persona.
– Árboles de decisión: Son modelos que se basan en la decisión de reglas binarias que permiten repartir observaciones dependiendo de sus atributos. Así, la asignación de una hipoteca puede ser evaluada de manera cuantitativa y posteriormente concedida.
– Random Forests: Es una combinación de árboles de decisión y utiliza la “votación mayoritaria” para tomar decisiones. Esto significa que el modelo toma la decisión que más se ha elegido entre los árboles de decisión individuales.
– K-means: Es un algoritmo de clustering que divide un conjunto de datos en “k” grupos de similares basándose en características específicas. Por ejemplo, un modelo de k-means podría utilizarse para agrupar a los clientes de un banco en diferentes categorías basándose en su perfil de inversión.
– Redes Neuronales: se inspira en el funcionamiento del cerebro humano y utiliza una serie de nodos interconectados para procesar y analizar datos. Tiene aplicabilidad en clasificación y predicción de valores continuos.
En Resumen
Las técnicas de Machine Learning como modelos estadísticos son herramientas que permiten el procesamiento de datos de manera más eficiente que simplemente tener la información que no es directamente interpretable. A medida que la cantidad de datos disponibles sigue creciendo, es probable que el aprendizaje automático siga siendo una herramienta cada vez más importante en el sector bancario y en muchas otras industrias, por lo que se convierte en un interés primordial mantenerse constantemente actualizado para sacar el máximo provecho de las tecnologías que, sin duda, están en su momento más acelerado de desarrollo.
Referencias:
- Jordan, M. I. (1986). “Serial Order: A Parallel Distributed Processing Approach”. Psychological Review, 93(2), págs. 281-311.
- Friedman, J. H. (1989). “CART: Classification and Regression Trees”. Technical Report, Department of Statistics, Stanford University.
- Platt, J. (1990). “Fast Training of Support Vector Machines Using Sequential Minimal Optimization”. Advances in Kernel Methods – Support Vector Learning, MIT Press, págs. 185-208.
- Rumelhart, D. E., Hinton, G. E. y Williams, R. J. (1986). “Learning representations by back-propagating errors”. Nature, 323, págs. 533-536.
- Hand, D. J., Henley, W. E., & Daly, L. (2001). Credit scoring and its applications. Statistics in practice, John Wiley & Sons.
- Verbeke, W., Martens, D., & Baesens, B. (2004). Customer segmentation using data mining techniques. In Customer relationship management: concepts and tools (pp. 121-141). Springer, Boston, MA.
- Martin Leo & Suneel Sharma & K. Maddulety, 2019. “Machine Learning in Banking Risk Management: A Literature Review,” Risks, MDPI, vol. 7(1), pages 1-22, March.
- Simeone, A., Spagnoletti, P., & Bianchi, G. (2004). A comparison of neural network and decision tree classifiers. Decision Support Systems, 37(3), 341-358.
- Zakrzewska and J. Murlewski, “Clustering algorithms for bank customer segmentation,” 5th International Conference on Intelligent Systems Design and Applications (ISDA’05), 2005, pp. 197-202, doi: 10.1109/ISDA.2005.33.





